미뤘던 transformer 아키텍처입니다
저는 최대한 원 논문 위주로 이해하려고 노력하는데 transformer는 논문만 보고 이해하는 것은 거의 불가능합니다
영상 및 다른 자료들을 여러개 보는 것을 추천합니다
Overview

1. 단어들을 한번에 전달합니다
- 단어가 한번에 1개씩 들어가는 RNN과 달리 모든 단어들을 한번에 전달받고, Positional Encoding으로 단어의 순서를 표시합니다
2. Encoder : query / key / value를 이용하여 문맥 정보를 이해하는 단계입니다
- Input끼리의 단어들간의 관계를 학습합니다
3. Decoder : 이전 예측을 입력으로 받아 다음 단어를 예측합니다
- 이 과정에서 Encoder의 key와 value를 전달받아 Input의 전반적인 문맥을 이해하도록 돕습니다
1번부터 차근차근 살펴봅시다
Positional Encoding
Transformer에서 모든 input은 한번에 들어갑니다
단어가 임베딩되어 모델안으로 들어가게 되면 각 임베딩된 단어들은 본인들이 앞/뒤에 있는 단어들이 어떤 단어인지 모릅니다
하지만, 단어의 순서에 따라 의미가 달라질수있는 언어의 특성상 단어의 순서를 아는 것은 매우 중요합니다
기존의 RNN은 순서대로 단어를 집어넣어주는 것으로 순서 정보를 함께 넣어 줄 수 있었고,
그대신 Transformer는 Positional Encoding을 통해 단어의 순서를 기억합니다
Embedding된 단어에 다음과 같은 Positional Encoding을 더합니다
PE(pos,2i)=sin(pos/100002i/dmodel)
PE(pos,2i+1)=cos(pos/100002i/dmodel)
이 과정에서 별도의 weight나 bias는 없으며 단순 element-wise addition입니다
dmodel은 임베딩된 단어의 차원입니다
i는 몇번째 차원에 있는지를 나타내는 것입니다
참고로, 트랜스포머에서 단어들은 BPE로 인코딩(임베딩) 되었다고 합니다
BPE는 다른 글에서 다루겠습니다
왜 저러한 PE를 썼는지는 원 논문에서는 다음 한 문장으로만 되어있습니다
PE(pos+k) can be represented as a linear function of PE(pos)
의미를 살펴봅시다
문장1: I like dogs and cats.
문장2: No one likes dogs and cats.
dogs와 cats라는 단어를 주목해봅시다
문장1에서는 각각 3번째 5번째에 등장하고
문장2에서는 각각 4번째 6번째에 등장합니다.
하지만, 단어가 언제 등장하든 상관없이, dogs와 cats가 2만큼 떨어져있다면 두 단어간의 관계는 똑같아야 합니다
PE벡터는 pos를 기준으로 k만큼 떨어진 단어에 대해 다음과 같은 관계성이 있습니다
→PE(pos+k)=Dk⋅→PE(pos)
Dk=[cos(k100000/d)−sin(k100000/d)00⋯00sin(k100000/d)cos(k100000/d)00⋯0000cos(k100002/d)−sin(k100002/d)⋯0000sin(k100002/d)cos(k100002/d)⋯00⋮⋮⋮⋮⋱⋮⋮00000cos(k10000(d−2)/d)−sin(k10000(d−2)/d)00000sin(k10000(d−2)/d)cos(k10000(d−2)/d)]
따라서, PE(pos+k)는 PE(pos)의 linear function으로 표현할 수 있습니다
그리고 이를 통해 단어간의 위치에 따른 관계를 나타낼 수 있습니다
Position Encoding은 논문에서는 간략히 설명되어 있지만, 왜 저렇게 표현되었는지에 대한 자세한 설명은 아래 블로그를 참고 바랍니다
(저는 처음에 PE(pos+k) = PE(pos) + D(k) 꼴로 되어야하지 않나 생각을 했었지만 이렇게 표현하면 k커질수록 PE의 값이 너무 커지기 때문에 임의의 길이의 문장에 적용이 불가합니다)
https://towardsdatascience.com/master-positional-encoding-part-i-63c05d90a0c3
Encoder
Encoder에서는 self-attention layer와 feed forward layer를 통과합니다
Self attention의 의미는 위 그림에서 볼 수 있습니다
사람은 it이 animal을 가리키고 있다는 사실을 알고있지만 기계는 알지 못합니다
self attention은 transformer가 각 단어가 어떠한 단어들과 연관이 있는지 알려줍니다
Self Attention
self attention을 어떻게 구하는지 알아봅시다
모든 임베딩 벡터(positional encoding을 통과한)에 각 weight를 곱해 query, key, value라는 것을 만듭니다
query / key : attention score를 구해서 각 단어들이 다른 단어들과 얼마만큼 가중치가 필요한지 계산
value : 각 단어의 실제 의미를 나타내는 벡터
I like pizza에 self attention을 적용하는 예시를 보겠습니다
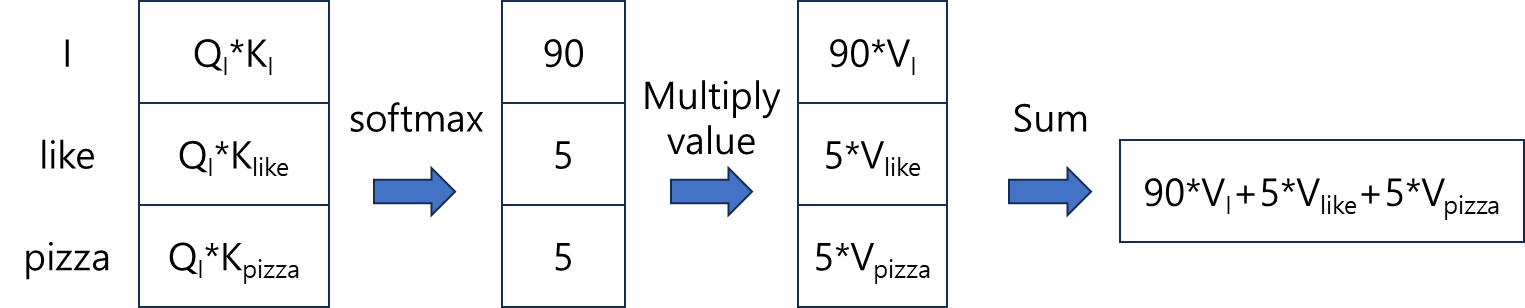
I에 attention을 적용한 결과입니다
그림과 같이 query와 key를 곱하여 score를 구하고 value를 곱해 최종적으로 단어 I에 대한 context-aware한 representation을 얻습니다
I / like / pizza 3개의 단어에 동일한 방법을 적용시켜줍니다
실제로 계산할때는 I / like / pizza 각각 3번 따로 연산을 하지 않습니다
각 단어에 대해 query, key, value 모두 벡터이기 때문에, query, key, value를 합쳐 하나의 행렬로 만들어서 행렬곱으로 한번에 계산합니다
따라서 Attention을 수식으로 표현하면 다음과 같습니다
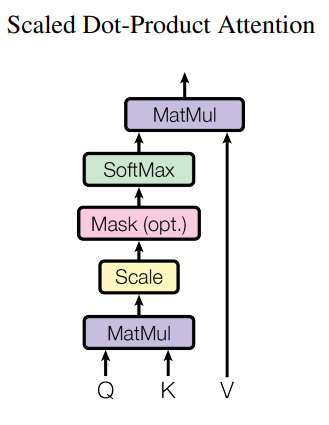
Attention(Q,K,V)=softmax(QKT√dk)V
√dk가 갑자기 등장했습니다
dk는 Q와 K의 차원의 크기입니다
key백터가 늘어날수록 값의 크기가 늘어나서 위와 같은 연산을 추가했습니다
Multi-head Attention
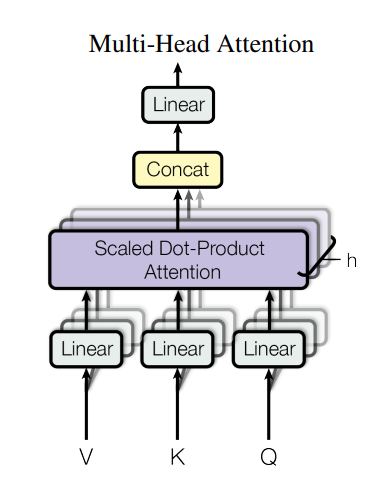
attention 파라미터에 따라 문맥정보를 보는 방식이 다를 수 있습니다
multi-head attention은 다양한 방식으로 정보를 처리하여 모델이 다양한 관점에서 문맥 정보를 파악하도록 합니다
MultiHead(Q,K,V)=Concat(head1,...,headh)WO
headi=Attention(QWQi,KWKi,VWVi)
논문에서는 h=8입니다
Decoder
입력 시퀀스로 부터 다음 단어 1개를 예측합니다
다음과 같은 번역기를 만든다고 가정해봅시다
입력 : I / am / a / student
출력 : 저는 / 학생 / 입니다
1. (Encoder의 문맥정보) + <start> => [저는] 예측
2. (Encoder의 문맥정보) + <start> / 저는 => [학생] 예측
3. (Encoder의 문맥정보) + <start> / 저는 / 학생 => [입니다] 예측
4. (Encoder의 문맥정보) + <start> / 저는 / 학생 / 입니다 => [<end>] 예측
하지만, 이렇게 sequential하게 처리하면 시간복잡도가 O(N)만큼 소요됩니다
Masked Attention
안쓰는 단어들은 Masking해서 softmax를 통과할때 0이 되도록 유도합니다
예를들어
2. (Encoder의 문맥정보) + <start> / 저는 => [학생] 예측
를 할때
학생 / 입니다 / <end> 는 사용하지 않는 단어이므로,
score를 -inf로 만듭니다
이를 통해 병렬로 연산을 수행할수있습니다
Encoder의 문맥정보
encoder의 문맥정보가 어떻게 decoder로 넘어갈수있는지 알아봅시다
Transformer 아키텍처를 다시 가져오겠습니다
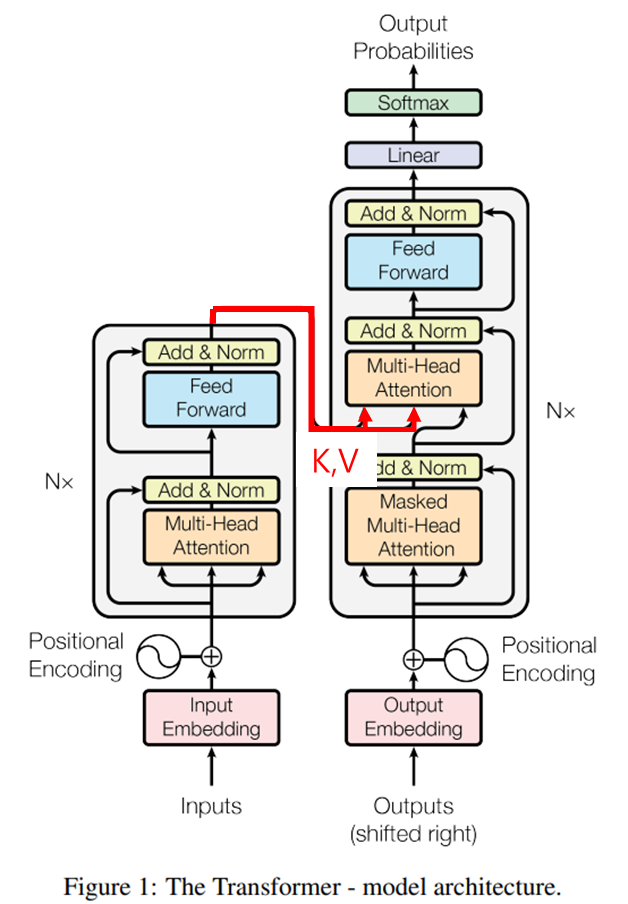
Masked Multi head attention을 통과한 값이 Query로 쓰이고 Encoder의 결과가 Key와 Value로 쓰입니다
이를 통해 다시 score를 계산하고 attention연산을 수행합니다
Encoder and Decoder Stacks
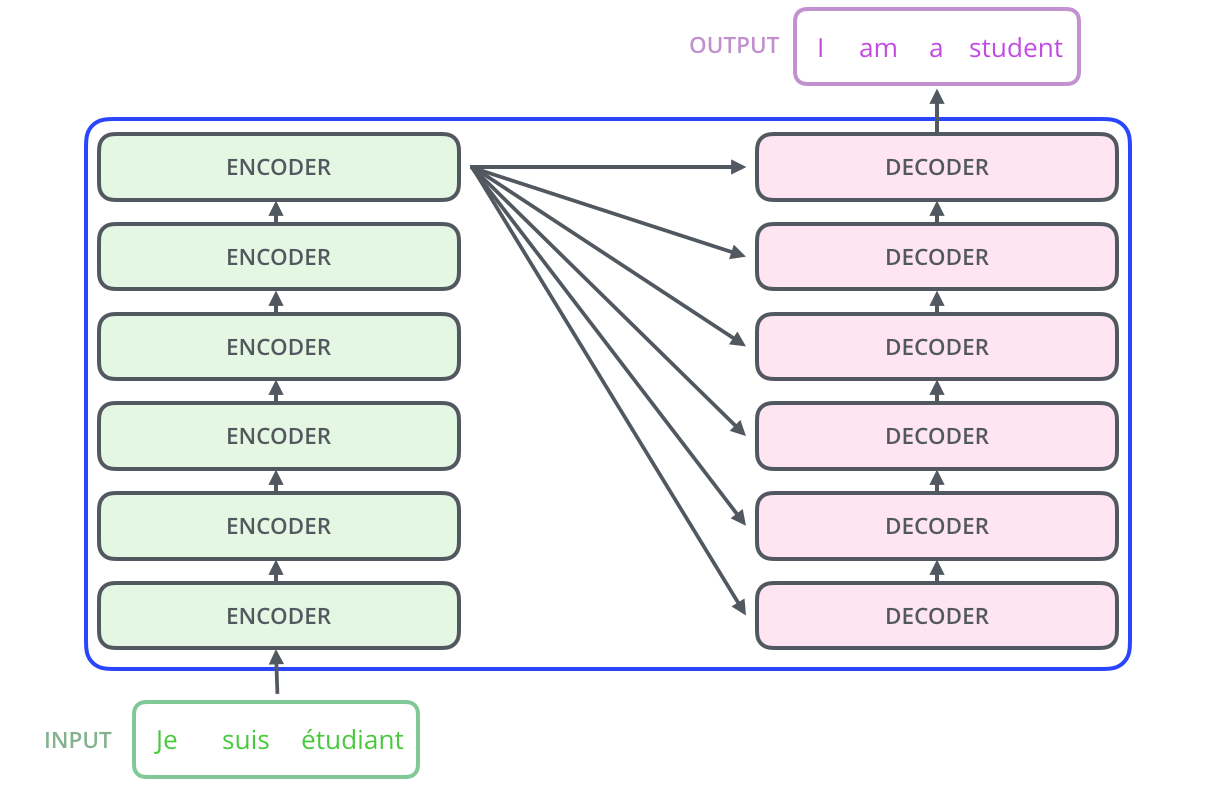
모델을 더 깊게 만들기 위해 encoder와 decoder를 여러번 쌓는 구조로 되어있습니다
논문에서는 N=6입니다
https://arxiv.org/pdf/1706.03762
'인공지능 > 기타' 카테고리의 다른 글
| Backpropagation for a Linear Layer (0) | 2024.10.31 |
|---|---|
| 라그랑주 승수법 (Lagrange multipliers) (0) | 2024.08.05 |
| [강화학습 요약] Policy Gradient (0) | 2023.10.15 |
| [강화학습 요약] SARSA / VFA / DQN (1) | 2023.09.11 |
| [강화학습 요약] Policy Iteration / MC / TD learning (0) | 2023.08.27 |