요약
일반적으로 teacher의 특징을 student에 학습시키는 knowledge distillation과 달리,
teacher 모델 없이 하나의 모델에서 깊은 layer의 특징을 얕은 layer에 학습시킨다
https://arxiv.org/pdf/1905.08094.pdf
모델구조

ResNet의 각 ResBlock 마다 output이 연결되어있습니다 (deep supervision과 유사)
각 ResBlock은 Ground Truth만을 통해서 학습되는것이 아니라,
가장 깊은 classifier과 Softmax를 통해 각각의 feature와 softmax가 학습됩니다.
${\begin{align}
loss &= \sum_{i}^{C}loss_i \\
&= \sum_{i}^{C}((1-\alpha) \cdot CrossEntropy(q^i,y) + \alpha \cdot KL(q^i,q^C) + \lambda \cdot ||F_i-F_c||^2_2) \\
\end{align}}$
loss는 위와 같이 3가지로 구성되며 순서대로,
1. hard label과의 loss
2. deepest classifier와 shallow classifier 간의 softmax loss
3. deepest classifier와 shallow classifier 간의 feature loss
입니다
C는 classifier의 개수입니다. 참고로 가장 깊은 classifier에서 2, 3은 0입니다
inference에서 shallow classifier들은 쓰지 않습니다
성능

Baseline 모델에 비해 CIFAR100과 ImageNet 둘 다 큰 성능 향상을 보여주었습니다

shallow한 classifier는 baseline보다 더 빠른 성능을 보여주었습니다. depth를 어플리케이션의 요구사항에 따라 다르게 가져갈 수 있습니다. (Adaptive Computation)
왜 잘 동작할까
단순히 feature와 softmax를 추가적으로 학습해서 성능이 좋아졌다는 설명외에 추가적인 설명이있습니다
Bottleneck layer
deep supervision은 vanishing gradient을 해결하기 위해 classifier마다 hidden layer를 추가적으로 직접 학습하는 방법입니다. 하지만, hidden layer의 성능을 높이는 것이 output layer의 성능 향상에 방해가 될 수 있습니다. bottleneck을 통해서 feature를 학습하게 만들어 shallow layer간의 영향도를 낮추었습니다. 이로써 deep supervision의 좋은 점은 가져가면서, 나쁜 점은 개선했습니다. 또한, bottleneck layer를 통해 중요한 feature를 학습하게 할 수 있습니다.
Flat minima
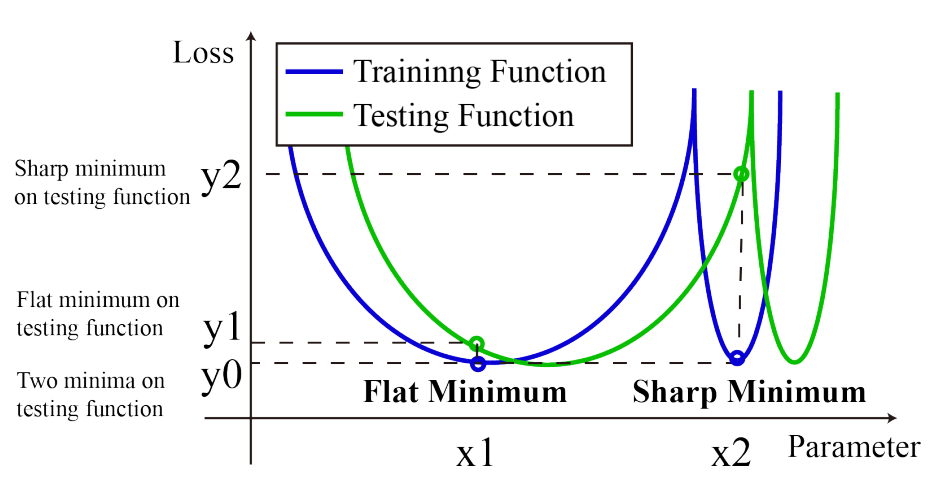
일반적으로 sharp minima보다 flat minima에 위치할 때 더 좋은 성능을 보인다고 합니다. (sharp minima는 noise에 취약) 파라미터가 많으면 flat minima에 안착하기 쉽습니다. (On large-batch training for deep learning: Generalization gap and sharp minima)
아마 논문의 저자는 self distillation을 통해 baseline보다 더 많은 파라미터로 학습하므로 flat minima에 안착했다고 얘기하고 있는 것 같습니다 (실험적으로 증명은 함)
코드
논문에는 깃허브에 곧 코드를 올리겠다고 하였으나, 어디있는지 못 찾았습니다.
대신 이 논문을 바탕으로 pytorch로 구현한 분이 계신데, 신기한점은 Resnet50에서 논문보다 더 좋은 성능을 보이는 hyperparameter를 찾았습니다
https://github.com/luanyunteng/pytorch-be-your-own-teacher?tab=readme-ov-file#result-on-resnet50