요약

큰 데이터셋에 한해서 vanilla KD가 다른 기법들과 차이가 거의 나지 않는다
Small-scale dataset vs Large-scale dataset

Previous recipe는 원 논문의 결과이고 stronger recipe는 다른 training 기법을 쓴 것 입니다
original paper의 기법만으로는 DKD나 DIST와 vanilla-KD와 확연한 차이를 보여줍니다
stronger recipe에서는 Cifar100은 2400 epoch만큼 학습했고 ImageNet-1K는 30%/60%/full은 각각 4000/2000/1200 epoch만큼 학습을 돌렸고 augmentation도 했습니다. 이러한 기법들로 학습을 더 돌렸을때, ImageNet-1k에서는 DKD나 DIST같은 방법과 비교했을 때 크게 차이나지는 않았습니다
이러한 사실을 저자는 small data pitfall 라고 표현합니다
Hint-based vs logit-based


Resnet 50을 student 모델로 한 결과입니다.
모든 logit-based approach가 hint-based approach 보다 좋은 성능을 보였습니다
student와 teacher의 차이가 날수록 hint-based approach는 teacher를 따라하는 것이 오히려 방해가 되는 것 같다는 것이 저자의 생각입니다. 또한 서로 다른 구조의 모델에서 hint-based approach를 쓴다면 다른 구조의 모델의 feature는 잘 담을 수 없습니다
A1 setting으로 600 epoch일 때는 vanilla KD가 가장 좋은 성능을 보이기도 했습니다.
또한, epoch이 크게 늘어나도 꾸준한 성능의 향상을 보였습니다.
지금까지의 연구는 small-scale dataset 위주의 연구만 있었어서 vanilla KD의 성능이 좋게 나오지 않았다는 평입니다
Ablation Study
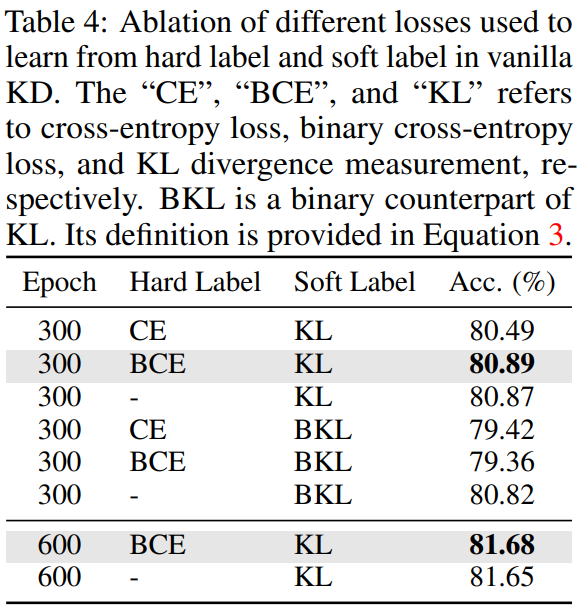
Loss function을 다르게 하여 실험을 진행한 결과입니다.
hard label가 모델의 성능에 영향을 크게 주지 못하고 있습니다.
Hard Label이 -로 되어있는건 hard label을 학습에 반영하지 않았다는 것 같은데 코드에 Hard label사용하지 않는다는 설정은 코드에 안보이는 것 같아서 저 부분은 다시 봐야할것같습니다. 만약에 그게 맞다면 hard label을 사용하지 않는게 CE를 썼을 때 보다 성능이 잘 나온다는 의미입니다

위는 모델의 파라미터 수에 따른 knowledge distillation 실험 결과입니다
teacher는 BEiTv2-L이 더 크지만 실질적으로 좋은 성능은 보여주고 있지 않습니다
결론
teacher와 student간의 차이가 클수록 teacher가 배운 내용을 student가 제대로 학습하지 못한다는 것은 기존에 밝혀진 바였고 이로 인해 파생된 방법들이 많습니다. large-scale data에서 새로운 방법들이 잘 통하지 않는 것은 output label이 복잡할수록 student와 teacher의 차이를 줄여주진 못한 것 같습니다.
이러한 현상이 일어나는 이유를 조금 더 설명을 해줬다면 좋았을 것 같은데 개인적으로 왜 이러한 현상이 일어나는지 직관적으로 와닿지는 않습니다
'인공지능 > Knowledge Distillation' 카테고리의 다른 글
| Improving Knowledge Distillation via Regularizing Feature Norm and Direction (0) | 2024.08.16 |
|---|---|
| Logit Standardization in Knowledge Distillation (0) | 2024.08.08 |
| Knowledge Distillation from A Stronger Teacher (0) | 2024.07.14 |
| Self Distillation - Be Your Own Teacher (0) | 2024.04.12 |